Prema Međunarodnoj uniji za telekomunikacije, u 2016. godini internet je, s određenim stupnjem regularnosti, koristilo tri i pol milijarde ljudi. Većina njih čak i ne misli da su poruke koje šalju putem računala ili mobilnih naprava, kao i tekstovi prikazani na različitim monitorima, zapravo kombinacije s 0 i 1. Takav prikaz informacija naziva se kodiranje. On osigurava i uvelike olakšava njegovo skladištenje, obradu i prijenos. Godine 1963. razvijen je američki ASCII kod koji je također posvećen ovom članku.
Prikaz informacija u računalu
Sa stajališta bilo kojeg računala, tekst je skup zasebnih znakova. Oni uključuju ne samo slova, uključujući velika, nego i znakove interpunkcije, brojeve. Osim toga, posebni znakovi su "=", "& amp;", "(" i razmaci). Skup znakova iz kojih se tekst sastoji se zove abeceda, a njihov broj je snaga (označena kao N). = 2 ^ b, gdje je b broj bitova ili težina informacija određenog znaka. Dokazano je da 256-znakovna abeceda omogućuje prikaz svih potrebnih znakova. Budući da je 256 8 stupnjeva dvojke, težina svakog znaka je jednaka 8 bita. zove se 1 bajt, tako da je uobičajeno reći da je binarni kod bilo koji znak u tekstu pohranjenom naračunalo, uzima jedan bajt memorije.
Kako se vrši kodiranje
Svaki se tekst unosi u memoriju osobnog računala pomoću tipke na tipkovnici koja sadrži brojeve, slova, interpunkcijske znakove i druge znakove. U RAM-u se prenose u binarnom kodu, to jest, svaki znak je poznat osobi od deset znamenki koda od 0 do 255 koji odgovara binarnom kodu od 00000000 do 11111111. za obradu teksta, pogledajte svaki znak zasebno. U isto vrijeme, 256 znakova je sasvim dovoljno da predstavljaju bilo koju simboličku informaciju.
ASCII kodiranje znakova
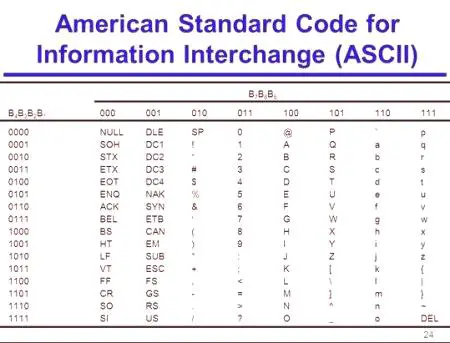
Ova kratica na engleskom jeziku tumači se kao američki standardni kod za razmjenu informacija. Čak i na početku kompjuterizacije postalo je očito da možete smisliti različite načine za kodiranje informacija. Međutim, za prijenos informacija s jednog računala na drugo bilo je potrebno razviti jedinstveni standard. Tako se 1963. u SAD-u pojavila ASCII tablica kodiranja. U njemu se svaki znak računalne abecede stavlja u korespondenciju s njegovim serijskim brojem u binarnom prikazu. U početku, ASCII kodiranje je korišteno samo u Sjedinjenim Državama, a zatim je postao međunarodni standard za računala.
Sadržaj
ASCII kodovi su podijeljeni u 2 dijela. Međunarodni standard smatra se samo prvom polovicom ove tablice. Sadrži znakove s rednim brojevima od 0 (kodirani kao 00000000) do 127 (kod 01111111).
Redni broj N
Kodiranje ASCII Tekst
Simbol
0 - 31
00000000 - 00011111
37)
Simboli iz N od 0 do 31 nazivaju se kontrolori. Njihova je funkcija usmjeravati proces izlaza teksta na monitor ili uređaj za ispis, sondiranje signala itd.
32 - 127
00100000 - 01111111
Znakovi od N od 32 do 127 (standardni dio tablice) su velika i mala slova latinice, 10 znamenki, interpunkcijski znakovi, kao i različite zagrade, komercijalne itd. znakova. Simbol 32 označen je razmakom.
128 - 255
10000000 - 11111111
Simboli iz N od 128 do 255 alternativni dio tablice ili kodne stranice) mogu imati različite opcije, od kojih svaka ima svoj broj. Kodna stranica se koristi za označavanje nacionalnih pisama koje se razlikuju od latinskog. Posebno koristi ASCII kodiranje za ruske znakove.
U tablici kodiranja, velika i mala slova slijede se abecednim redom, a brojevi - kako se vrijednosti povećavaju. Ovo načelo ostaje za rusku abecedu.
Kontrolni znakovi
ASCII tablica kodiranja izvorno je stvorena za primanje i prijenos informacija preko dugog neiskorištenog uređaja kao što je teletype. S tim u vezi, neprevedeni, korišteni kao naredbe za upravljanje ovim uređajem bili su uključeni u skup znakova. Slični su timovi također korišteni u računalnim metodama slanja poruka kao Morseovim kodom, itd.
Najčešći "teletype"simbol je NUL (00 "nula"). I dalje se koristi u većini programskih jezika, označavajući kraj retka.
Gdje se može primijeniti ASCII kodiranje
Američki standardni kod nije potreban samo za unos tekstualnih podataka pomoću tipkovnice. Također se koristi u grafikonu. Konkretno, u ASCII Art Maker programu, slika različitih ekstenzija je spektar ASCII kodiranja znakova. Slični proizvodi mogu biti dva tipa: obavljaju funkciju grafičkih urednika pretvaranjem slike u tekst i pretvaranjem "crteža" u ASCII grafikon. Na primjer, dobro poznati smajliji je živ primjer primjerka kodiranja.
ASCII se također može koristiti pri izradi HTML dokumenta. U tom slučaju možete unijeti određeni skup znakova, a kada pogledate stranicu pojavljuje se simbol koji odgovara tom kodu. ASCII je također potreban za stvaranje višejezičnih stranica, jer znakovi koji nisu dio određene nacionalne tablice zamjenjuju se ASCII kodovima.
Neke značajke
Za kodiranje tekstualnih informacija u ASCII kodiranju, u početku se koristilo 7 bitova (jedan je ostao prazan), ali danas radi kao 8-bitni. Slova, koja se nalaze u stupcima smještenim na vrhu i na dnu, razlikuju se jedni od drugih samo jedan bit. To uvelike smanjuje složenost testa.
Korištenje sustava Microsoft Office ASCII
Ako je potrebno, ovu vrstu kodiranja tekstualnih informacija mogu koristiti Microsoftovi programeri za obradu teksta, kao što su Notepad i Office Word.Međutim, prilikom pisanja teksta u ovom slučaju bit će nemoguće koristiti neke opcije. Na primjer, nećete moći dodijeliti podebljano, jer ASCII kodiranje zadržava samo sadržaj informacija, ignorirajući njegov ukupni izgled i oblik.
Standardizacija
ISO je usvojio norme ISO 8859. Ova skupina definira kodiranje od osam znakova za različite jezične skupine. ISO 8859-1 - Prošireni ASCII je tablica za Sjedinjene Države i zapadnoeuropske zemlje. I ISO 8859-5 je tablica koja se koristi za ćirilicu, uključujući i za ruski jezik. Iz niza povijesnih razloga, ISO 8859-5 je korišten za vrlo kratko vrijeme. Kod ruskog jezika kodiranje se trenutno koristi:
CP866 (kodna stranica 866) ili DOS, što se često naziva alternativnim GOST kodiranjem. Aktivno je korištena sve do sredine 90-ih godina prošlog stoljeća. Trenutno se praktički ne koristi. KOI-8. Kodiranje je razvijeno sedamdesetih i osamdesetih godina prošlog stoljeća, a trenutno je standardni standard za poruke e-pošte u RuNetu. To je naširoko koristi u Unix operativnim sustavima, uključujući Linux. "Ruska" verzija KOI-8 naziva se KOI-8R. Osim toga, postoje verzije za druge ćirilične jezike, primjerice ukrajinski. Kodna stranica 1251 (CP 1251 Windows-1251). Dizajniran od strane Microsofta za podršku ruskom jeziku u Windows okruženju. Glavna prednost prvog standarda CP866 bila je očuvanje pseudografskih znakova na istim položajima kao i kod proširenog ASCII-a. Dopušteno je trčanje bez promjenatekstualne aplikacije u inozemstvu, kao što je poznati Norton Commander. Trenutno se CP866 koristi za programe razvijene u sustavu Windows koji rade u punom zaslonu u tekstualnom načinu ili u tekstnim okvirima, uključujući FAR Manager. Računalni tekstovi pisani CP866 enkripcijom rijetko se susreću u posljednje vrijeme, ali to je upravo ono što se koristi za ruska imena datoteka u Vindousu.Unicode
Trenutno se najčešće koristi ovo kodiranje. Unicode kodovi su podijeljeni na područja. Prvi (od U + 0000 do U + 007F) uključuje ASCII znakove s kodovima. Zatim postoje područja znakova različitih nacionalnosti, kao i znakovi interpunkcije i tehnički simboli. Osim toga, neki Unicode kodovi su rezervirani u slučaju potrebe za uključivanjem novih simbola u budućnosti.

Sada znate da je u ASCII kodiranju svaki znak predstavljen kao kombinacija 8 nula i jedinica. Za ne-stručnjake, ove informacije mogu izgledati nepotrebno i nezanimljivo, ali zar ne želite znati što se događa "u mozgu" vašeg računala?!