Kako doći do tečajeva SEO-promocije, novaci se susreću s velikim brojem razumljivih i ne baš pravovremenih. Sve to nije lako razumjeti, pogotovo ako je u početku bilo slabo objašnjeno ili izgubljeno neke od trenutaka. Razmotrite vrijednost u datoteci robots.txt Disallow, koja zahtijeva ovaj dokument, kako ga stvoriti i raditi s njom.
Jednostavnim riječima
Da ne bismo "hranili" čitatelja složenim objašnjenjima, koja se obično nalaze na specijaliziranim stranicama, bolje je sve objasniti "na prste". Tražilica stiže na vašu web-lokaciju i indeksira stranice. Nakon što vidite izvješća koja ukazuju na probleme, pogreške, itd.
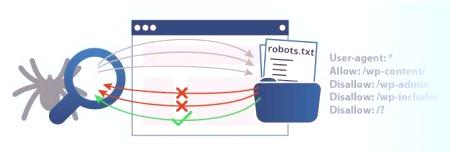
Ali stranice također imaju takve informacije koje nisu potrebne za statistiku. Na primjer, stranica "Tvrtka" ili "Kontakti". Sve je to neobvezno za indeksiranje, au nekim je slučajevima nepoželjno jer može narušiti statistiku. Da biste to izbjegli, najbolje je zatvoriti ove stranice s robota. Upravo to zahtijeva naredbu u datoteci robots.txt Disallow.
Standard
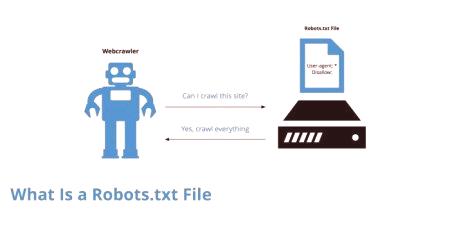
Ovaj je dokument uvijek dostupan na stranicama. Njegovo stvaranje rješavaju programeri i programeri. Ponekad to mogu učiniti i vlasnici resursa, osobito ako je mali. U ovom slučaju, rad s njim ne traje puno vremena. Robots.txt se naziva standardom za isključivanje tražilice. Prikazuje se dokumentom u kojem su propisana glavna ograničenja. Dokument se nalazi u korijenu resursa. U ovom slučaju, tako da se može naći uz put "/robots.txt". akoresurs ima nekoliko poddomena, a zatim je ova datoteka smještena u korijen svake od njih. Standard je kontinuirano povezan s drugim - Sitemapovima.
. Ovo je datoteka napisana u XML-u. Ona pohranjuje sve podatke o resursu za PS. Prema dokumentu možete saznati više o web stranicama indeksiranim prema djelima.
Datoteka omogućuje brzi pristup PS-u bilo kojoj stranici, pokazuje najnovije promjene, učestalost i važnost PS-a. Prema tim kriterijima, robot najpogodnije skenira stranicu. Ali važno je razumjeti da prisutnost takve datoteke ne osigurava indeksiranje svih stranica. To je više nagovještaj na putu prema ovom procesu.
Korištenje
Ispravna datoteka robots.txt koristi se dobrovoljno. Sam se standard pojavio 1994. godine. Prihvatio ga je konzorcij W3C. Od tog trenutka počeo se koristiti na gotovo svim tražilicama. To je potrebno za "dozirano" podešavanje skeniranja resursa od strane pretraživačkog robota. Datoteka sadrži skup uputa koje koriste FP. Zahvaljujući alatu, lako je instalirati datoteke, stranice, direktorije koji se ne mogu indeksirati. Robots.txt također ukazuje na datoteke koje je potrebno odmah provjeriti.
Zašto?
Unatoč činjenici da se datoteka zapravo može koristiti dobrovoljno, ona je kreirana od strane gotovo svih stranica. To je potrebno kako bi se pojednostavio rad robota. U suprotnom, provjerava sve stranice slučajnim redoslijedom, a osim što može preskočiti neke stranice, stvara veliki teret naresurs. Također, datoteka se koristi za skrivanje od očiju tražilice:
Stranice s osobnim podacima posjetitelja.
Stranice koje sadrže obrasce za slanje podataka, itd.
Zrcalna mjesta.
Stranice s rezultatima pretraživanja.
Ako ste specificirali robots.txt Disallow za određenu stranicu, postoji mogućnost da će se i dalje pojavljivati u tražilici. Ta se mogućnost može pojaviti ako je veza na stranicu postavljena na nekom od vanjskih resursa ili unutar vaše web-lokacije.
Direktive
Govoreći o zabrani tražilice, često se koristi pojam "direktive". Ovaj je pojam poznat svim programerima. Često se zamjenjuje sinonimom "instrukcija" i koristi se zajedno s "naredbama". Ponekad se može predstaviti skupom konstrukata programskih jezika. Direktiva Disallow u datoteci robots.txt je jedna od najčešćih, ali ne i jedina. Osim toga postoji nekoliko drugih koji su odgovorni za određene upute. Na primjer, postoji korisnički agent koji prikazuje robote tražilice. Dopusti se suprotna naredba zabrane. Označava dopuštenje za indeksiranje nekih stranica. Zatim, pogledajmo osnovne naredbe.
Business card
Naravno, u datoteci robots.txt, User Agent Disallow nije jedina direktiva, već jedna od najčešćih. Sastoji se od većine datoteka za male resurse. Posjetnica za bilo koji sustav je još uvijek naredba korisničkog agenta. Ovo pravilo je dizajnirano tako da upućuje na robote koji gledaju upute koje će biti zapisane u dokumentu. Trenutno ima 300 tražilica. Ako želite da svaki od njih slijediPo nekim pokazateljima, ne treba sve napisati. Bit će dovoljno da navedete "User-agent: *". "Asterisk" u ovom slučaju će pokazati sustavima da su takva pravila dizajnirana za sve tražilice. Ako stvarate upute za Google, morate navesti naziv robota. U tom slučaju koristite Googlebot. Ako je u dokumentu navedeno samo ime, druge tražilice neće prihvatiti naredbe robots.txt datoteke: Disallow, Allow, itd. Pretpostavit će da je dokument prazan i da za njih nema nikakvih uputa.
Potpuni popis botnama može se naći na internetu. To je vrlo dugo, pa ako trebate upute za određene Google usluge ili Yandex, morat ćete odrediti određena imena.
Zabrana
Već smo mnogo puta govorili o sljedećem timu. Disallow samo određuje koje informacije robot ne bi trebao čitati. Ako tražilicama želite prikazati sav sadržaj, samo napišite "Disallow:". Tako će posao skenirati sve stranice vašeg izvora. Potpuna zabrana indeksiranja datoteke robots.txt "Disallow: /". Ako pišete na ovaj način, rad neće uopće skenirati resurs. To se obično radi u početnim fazama, u pripremi za pokretanje projekta, u eksperimentima, itd. Ako je stranica spremna za prikazivanje, onda promijenite ovu vrijednost tako da se korisnici mogu upoznati s njom. Općenito, tim je univerzalan. Može blokirati određene stavke. Na primjer, mapa s naredbom Disallow: /papka /može zabraniti indeksiranje veze do datoteke ili dokumenata određene dozvole.
Dopuštenje
Dopustiti radpogledati određene stranice, datoteke ili direktorije pomoću direktive Allow. Ponekad je potrebna naredba da robot posjeti datoteke iz određenog odjeljka. Na primjer, ako je ovo mrežna trgovina, možete odrediti direktorij. Ostale stranice će biti skenirane. Ali zapamtite da najprije morate zaustaviti pregledavanje cijelog web-mjesta, a zatim na otvorenim stranicama odredite naredbu Dopusti.
Ogledala
Još jedna smjernica domaćina. Ne koriste ga svi webmasteri. Potrebno je ako vaš resurs ima zrcala. Tada je potrebno ovo pravilo, jer ukazuje na rad "Yandex" na kojem je ogledalo glavno i koje se mora skenirati. Sustav se ne luta i lako pronalazi traženi resurs prema uputama opisanim u datoteci robots.txt. U samoj datoteci stranica je napisana bez naziva "http: //", ali samo ako radi na HTTP-u. Ako koristi HTTPS protokol, on pokazuje taj prefiks. Na primjer, "Host: site.com" ako je HTTP ili "Host: https://site.com" u slučaju HTTPS-a.
Navigator
Već smo razgovarali o Sitemapovima, ali kao zasebnu datoteku. Gledajući pravila pisanja robots.txt s primjerima, vidimo korištenje slične naredbe. Datoteka se odnosi na "Sitemap: http://site.com/sitemap.xml". To je učinjeno tako da robot provjerava sve stranice koje su navedene na mapi mjesta na adresi. Svaki put kada se vratite, robot će vidjeti nova ažuriranja, izmjene i brže slanje podataka tražilici.
Dodatne naredbe
Ovo su osnovne smjernice koje upućuju na važne i potrebne naredbe. One su manje korisne, inije uvijek primjenjivo smjernice. Na primjer, puzati-kašnjenje postavlja vrijeme koji će se koristiti između učitavanje stranice. To je slabe poslužitelja, a ne na „put” svoju invaziju robota. Koristi se za određivanje parametara sekunde. Clean-param izbjegava dupliciranje sadržaja koji se razlikuje dinamičan adresu. Oni nastaju u slučaju da postoji funkcija za sortiranje. Tim će izgledati ovako: «Clean-parametar: ref /catalog/get_product.com».
Univerzalni
Ako ne znate kako napraviti pravilan robots.txt - ne zastrašujuće. Osim smjernica su univerzalne inačice ove datoteke. Oni mogu biti postavljeni na gotovo bilo koje web stranice. Iznimke mogu biti samo veliki resurs. No, u ovom slučaju, datoteka treba znati profesionalci i učiniti ih posebne ljude.
Univerzalni set smjernica može otvoriti sadržaj stranica za indeksiranje. Tu je domaćin i ukazuje na karti registracija stranica. To vam omogućuje da rade uvijek možete pronaći na stranici potrebno za skeniranje. Kvaka je u tome što se podaci mogu varirati ovisno o sustavu, što je vaša imovina. Dakle, pravila moraju biti izabrani od strane gleda na vrstu web stranica i CMS-a. Ako niste sigurni što datoteku koju ste stvorili točna, možete provjeriti alat webmaster i Google „Yandex”.
Pogreške
Ako ste razumjeli što to znači u robots.txt zabraniti ne daje garanciju da neće ići u krivu kada stvarate dokument. Postoji nekoliko tipičnih problema koji se javljaju u ne-tehničke korisnike. Često miješati spomenutu direktivu. To može bitipovezan je s nesporazumom i neznanjem uputa. Možda ste to jednostavno ignorirali i prekinuli nemarnost. Na primjer, mogu koristiti "/" za User-agent, a za Disallow ime je robot. Prijenos je još jedna uobičajena pogreška. Neki korisnici vjeruju da bi popis zabranjenih stranica, datoteka ili mapa trebao biti naveden jedan po jedan za redom. Zapravo, za svaku zabranjenu ili dopuštenu vezu, datoteku i mapu morate ponovno napisati naredbu i iz nove linije. Pogreške mogu uzrokovati pogrešno ime same datoteke. Zapamtite da se zove "robots.txt". Koristite mala slova za ime, bez varijacija poput "Robots.txt" ili "ROBOTS.txt".
Polje korisničkog agenta uvijek treba popuniti. Nemojte ostavljati ovu direktivu bez naredbe. Kada se ponovno vratite na host, zapamtite da ako web-mjesto koristi HTTP, ne morate ga specificirati u naredbi. Samo ako je riječ o naprednoj inačici HTTPS-a. Smjernicu Disallow ne možete ostaviti besmislenom. Ako je ne trebate, jednostavno je nemojte usmjeravati.
Zaključci
Ukratko, vrijedi reći da je robots.txt standard koji zahtijeva točnost. Ako ga nikad niste susreli, tada ćete u ranim fazama stvaranja imati mnoga pitanja. Najbolje je dati ovaj posao webmasterima jer oni stalno rade s dokumentom. Osim toga, može doći do nekih promjena u percepciji direktiva od strane tražilica. Ako imate malu web-lokaciju - malu online trgovinu ili blog - tada će biti dovoljno proučiti ovo pitanje i uzeti jedan od univerzalnih primjera.

 Datoteka omogućuje brzi pristup PS-u bilo kojoj stranici, pokazuje najnovije promjene, učestalost i važnost PS-a. Prema tim kriterijima, robot najpogodnije skenira stranicu. Ali važno je razumjeti da prisutnost takve datoteke ne osigurava indeksiranje svih stranica. To je više nagovještaj na putu prema ovom procesu.
Datoteka omogućuje brzi pristup PS-u bilo kojoj stranici, pokazuje najnovije promjene, učestalost i važnost PS-a. Prema tim kriterijima, robot najpogodnije skenira stranicu. Ali važno je razumjeti da prisutnost takve datoteke ne osigurava indeksiranje svih stranica. To je više nagovještaj na putu prema ovom procesu.