Kodiranjem informacija u računalo podrazumijeva se proces pretvaranja u oblik koji omogućuje organiziranje prikladnijeg prijenosa, pohranjivanja ili automatske obrade tih podataka. U tu svrhu koriste se različite tablice. ASCII kodiranje je prvi sustav razvijen u Sjedinjenim Državama za rad s engleskim tekstom, koji je naknadno distribuiran širom svijeta. Njegov opis, svojstva, svojstva i daljnja uporaba posvećena je donjem članku.
Prikaz i pohranjivanje podataka u računalu
Simboli na računalnom monitoru ili mobilnom digitalnom gadgetu formiraju se na temelju skupova vektorskih oblika različitih kodnih simbola, što vam omogućuje da među njima pronađete simbol koji treba umetnuti u. trebate mjesto. To je niz bitova. Dakle, svaki znak mora odgovarati skupu nula i jedinica koje su u određenom, jedinstvenom poretku.
Kako je sve počelo
Povijesno gledano, prva računala su bila engleski. Za kodiranje karakternih podataka u njima bilo je dovoljno koristiti samo 7 bitova memorije, dok je za tu svrhu dodijeljen 1 bajt, koji se sastoji od 8 bita. Broj znakova koje je računalo razumjelo u ovom slučaju bilo je samo 128. Ti su se znakovi sastojali od engleske abecede sa svojim znakovima interpunkcije, brojevima i nekim posebnim znakovima. Englesko-sedmo-bitno kodiranje s odgovarajućom tablicom (kodna stranica), razvijeno 1963. godine, nazvano je American Standard Code za informacijeČvor. Tipično, kratica "ASCII kodiranje" je korištena i korištena za njezino označavanje.
Prijelaz na višejezičnost
Tijekom vremena, računala su postala široko korištena u zemljama koje ne govore engleski. U vezi s tim postojala je potreba za šifriranjem, dopuštajući uporabu nacionalnih jezika. Odlučeno je da se ne iznova pronalazi bicikl, kao i da se temelji ASCII. Tablica kodiranja u novom izdanju znatno se proširila. Pomoću osmog bita možete prevesti 256 znakova u računalni jezik.
Opis
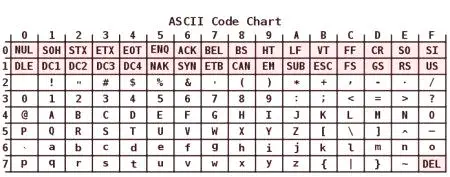
Kodiranje ASCII ima tablicu koja je podijeljena na 2 dijela. Smatra se da je općeprihvaćeni međunarodni standard tek njegova prva polovica. To uključuje:
simbole s rednim brojevima od 0 do 31 kodiranih sekvenci od 00000000 do 00011111. Oni su rezervirani za kontrolne znakove koji kontroliraju proces izlaza teksta na zaslon ili pisač, zvučnim signalom itd.
15) NN simboli u tablici od 32 do 127 kodiranih sekvenci od 00100000 do 01111111 čine standardni dio tablice. Oni uključuju prostor (N 32), slova latinice (velika i mala), deset-znamenkasti broj od 0 do 9 interpunkcijskih znakova, zagrade različitih linija i druge simbole.
Simboli sa serijskim brojevima od 128 do 255 kodirani sekvencama od 10.000.000 do 1100. Oni uključuju abecedna slova koja nisu latinska. Upravo taj alternativni dio tablice ASCII kodiranja koristi se za pretvaranje ruskih znakova u računalni oblik.
Neka svojstva
Značajke ASCII kodiranja uključuju kraticu malih i velikih slova "A" do "Z" samo jedan bit. Ova okolnost uvelike pojednostavljuje transformaciju registra, kao i njegovu provjeru pripadnosti određenom rasponu vrijednosti. Osim toga, sva slova u ASCII sustavu kodiranja prikazana su vlastitim rednim brojevima u abecedi, koji su zapisani s 5 znamenki u binarnom sustavu, ispred kojih su slova za mala slova 011 2, a gornja je 010 2. Među značajkama ASCII kodiranja, možete računati prikaz od 10 znamenki - "0" - "9". U drugom sustavu započinju s 00112 i završavaju s 2 vrijednosti brojeva. Dakle, 0101 2 je ekvivalent decimalnom broju od pet, tako da je "5" zapisano kao 001101012. Na temelju gore navedenog, možete lako pretvoriti binarne decimalne brojeve u niz u ASCII kodiranju dodavanjem lijevog slijednog bita od 00112 svakom pola bajtu.
Unicode
Kao što znate, tisuće znakova je potrebno za prikaz tekstova na jezicima skupine jugoistočne Azije. Takva količina nije opisana ni u jednom bajtu informacija, stoga čak i proširene verzije ASCII-a više ne mogu zadovoljiti rastuće potrebe korisnika iz različitih zemalja.
Stoga je postojala potreba za univerzalnim kodiranjem teksta, čiji je razvoj, u suradnji s mnogim vođama globalne IT industrije, preuzeo konzorcij Unicode. Njegovi stručnjaci kreirali su sustav UTF 32. U njemu je za kodiranje 1 znaka dodijeljeno 32 bita, koji se sastoje od 4 bajta informacija. Glavna stvarNedostatak je bio oštar porast količine memorije koja je zahtijevala čak 4 puta, što je zahtijevalo mnogo problema. Istodobno, za većinu zemalja s službenim jezicima koji pripadaju indoeuropskoj skupini, broj oznaka jednak je 2 32 više od viška. Kao rezultat daljnjeg rada stručnjaka iz Unicode konzorcija, pojavio se UTF-16 kodiranje. To je postala mogućnost pretvaranja simboličkih informacija, koje su bile složene i po količini potrebne memorije, i po broju kodiranih znakova. Zato je UTF-16 po defaultu prihvaćen i u njemu za jedan znak potrebno je rezervirati 2 bajta. Čak i ova prilično napredna i uspješna Unicode verzija imala je neke nedostatke, a nakon prebacivanja s proširene verzije ASCII na UTF-16, težina dokumenta je udvostručena. U tom smislu, odlučeno je da se koristi UTF-8 kodiranje promjenjive duljine. U ovom slučaju, svaki simbol izvornog teksta je kodiran u duljini od 1 do 6 bajtova.
Veza s američkim standardnim kodom za razmjenu informacija
Svi znakovi latinične abecede u UTF-8 promjenljive duljine kodirani su u 1 bajt, kao u ASCII sustavu kodiranja. Značajka UTF-8 je da ako je tekst na latinskom bez upotrebe drugih znakova, čak i programi koji ne razumiju Unicode, ipak će dopustiti da se pročita. Drugim riječima, osnovni dio kodiranja ASCII teksta jednostavno ulazi u novu UTF varijablu duljinu. Ćirilični znakovi u UTF-8 zauzimaju 2 bajta, a primjerice gruzijski - 3 bajta. Stvaranje UTF-16 i 8 riješilo je glavni problem stvaranja jedinstvenog prostora koda u fontovima. sOd tada, proizvođači fontova mogu ispuniti tablicu samo vektorskim oblicima znakova teksta na temelju njihovih potreba. Različiti operacijski sustavi daju prednost različitim kodiranjima. Da bi se mogli čitati i uređivati tekstovi upisani u različitom kodiranju, koriste se ruski programi za transkodiranje teksta. Neki uređivači teksta sadrže ugrađene enkodere i omogućuju čitanje teksta bez obzira na kodiranje.
Sada znate koliko znakova u ASCII kodiranju i kako i zašto je razvijeno. Naravno, danas je najrasprostranjenija u svijetu dobila standardni Unicode. Međutim, ne smije se zaboraviti da se temelji na ASCII-u, tako da vrijednost njegovih razvojnih inženjera u području IT-a treba biti dobro cijenjena.




 Sada znate koliko znakova u ASCII kodiranju i kako i zašto je razvijeno. Naravno, danas je najrasprostranjenija u svijetu dobila standardni Unicode. Međutim, ne smije se zaboraviti da se temelji na ASCII-u, tako da vrijednost njegovih razvojnih inženjera u području IT-a treba biti dobro cijenjena.
Sada znate koliko znakova u ASCII kodiranju i kako i zašto je razvijeno. Naravno, danas je najrasprostranjenija u svijetu dobila standardni Unicode. Međutim, ne smije se zaboraviti da se temelji na ASCII-u, tako da vrijednost njegovih razvojnih inženjera u području IT-a treba biti dobro cijenjena.