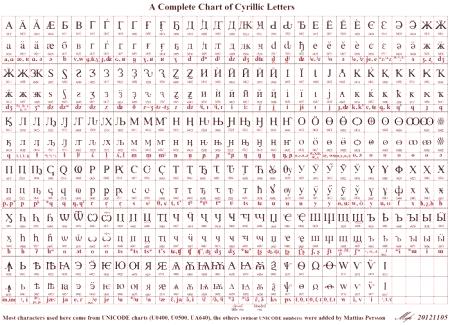
Unicode je međunarodni standard kodiranja znakova koji vam omogućuje prikaz teksta na bilo kojem računalu na svijetu na isti način, bez obzira na jezik sustava koji se na njemu koristi.
Osnove
Da bismo razumjeli što je potrebna tablica Unicode znakova, najprije ćemo razumjeti mehanizam prikazivanja teksta na zaslonu monitora. Računalo, kao što znamo, obrađuje sve informacije digitalno, ali da bi ga izveo za ispravnu percepciju osobe mora biti u grafici. Dakle, da bismo mogli pročitati ovaj tekst, moramo riješiti najmanje dva zadatka:
Kodirati tiskane znakove u digitalnom obliku. Omogućiti operacijskom sustavu usporedbu digitalnog oblika s vektorskim simbolima, drugim riječima, pronaći ispravna slova. Prvo kodiranje
Preteča svih kodiranja smatra se američkim ASCII. Opisao je englesku abecedu s interpunkcijskim znakovima i arapskim brojevima. 128 znakova koji su korišteni postali su temelj daljnjeg razvoja - koristi se čak i moderna Unicode tablica znakova. Od tada, prva slova u bilo kojem kodiranju zauzimaju slova latinice.
Svi ASCII-ovi dopuštali su spremanje 256 znakova, ali budući da su prvih 128 bili latinski, preostalih 128 je korišteno globalno za izradu nacionalnih standarda. Na primjer, u Rusiji, na njegovoj osnovi stvoreni su CP866 i KOI8-R. Te su se varijacije zvale proširenjaASCII verzije.
Kodirane stranice i Crazzybras
Daljnji razvoj tehnologije i pojavljivanje grafičkog sučelja doveli su do stvaranja ANSI kodiranja od strane Američkog instituta za standardizaciju. Za ruske korisnike, osobito s iskustvom, njegova verzija je poznata kao Windows 1251. Prvo je uvela koncept "kodne stranice". Uz pomoć kodnih stranica koje su sadržavale simbole nacionalnih pisama, osim latinskog, postojalo je "međusobno razumijevanje" između računala koja se koriste u različitim zemljama.
Međutim, prisutnost velikog broja različitih kodiranja korištenih za isti jezik, počela je uzrokovati probleme. Bilo je takozvanih karkozybrisa. Oni su nastali zbog nepodudarnosti izvorne kodne stranice na kojoj su neke informacije stvorene i kodne stranice koja se prema zadanim postavkama koristi na računalu krajnjeg korisnika.
Kao primjer, mogu se navesti gore spomenute ćirilične kodiranja CP866 i KOI8-R. Pisma u njima razlikovala su se po pozicijama kodova i načelima smještaja. U prvom su bili raspoređeni po abecednom redu, au drugom - na proizvoljan način. Možete zamisliti što se događalo pred očima korisnika koji je pokušao otvoriti takav tekst bez šifre koju želite ili pogrešnog tumačenja računala.
Stvaranje Unicoda
Širenje Interneta i srodnih tehnologija, kao što je e-pošta, dovelo je do činjenice da je tekstualna poruka na kraju prestala odgovarati svima. Vodeće tvrtke na tom područjuIT je stvorio Unicode konzorcij (Unicode Consortium), tablicu simbola koju je uvela 1991. pod imenom UTF-32, koja je dopuštala pohranu više od milijardu jedinstvenih znakova, što je bio najvažniji korak u dešifriranju tekstova.

Međutim, prva univerzalna tablica kodova znakova Unicode UTF-32 nije bila široko distribuirana. Glavni razlog bio je višak pohranjenih podataka. Brzo je izračunato da će za zemlje koje koriste latinicu, kodirane pomoću nove univerzalne proračunske tablice, tekst zauzimati četiri puta više prostora nego korištenje proširene ASCII tablice.